
The Europeana Newspapers project is collecting millions of high-resolution images of newspaper pages. The words in 10 million of these pages will be made fully searchable and integrated in an online browsing tool. Making these high-quality images available to researchers is far from straightforward. Below we outline one of the main obstacles, and the resulting solution.
The European Library is the project partner responsible for developing our historic newspapers browser. One of the biggest challenges they have faced while building this browser is the storage of extremely large files containing digitised newspaper images.
Why are the images so large? The process starts with the libraries undertaking the digitisation work. They create individual master files of each page and each of these files ranges between 10 and 50 MB.
These images are then made available to The European Library, which in turn shares them with researchers via its historic newspapers browser. To make the images useful to researchers, each image needs to be up to 2.5MB in size. Anything less won’t do since words, characters and images would be too blurry to examine properly.
If we assume an average image size of 1.5MB, making 10 million images available would demand a total server space of around 14 Terabytes. This is not sustainable in the long run.
Improved Image Retrieval Technique
The European Library technical team has come up with a new solution. Instead of centrally harvesting all the images and storing these on The European Library’s servers, numerous libraries have made it possible to directly access their image servers. This means that each library’s own hardware space, where suitably sized images are already stored, can be utilised. When a user searches on The European Library site and asks to see a particular image, a request is then sent to out to the original library to dynamically grab an image from the source library’s server and bring it into view.
Take this 1849 issue of the Viennese newspaper, Wiener Zeitung, for example. This digitised newspaper from the Austrian National Library allows the user to have full functionality over the image. One can zoom in and out and fully explore the image within The European Library interface even though the digital version remains housed on a server in Vienna.

This approach has another advantage in that it lets the curator of the original material maintain control over the digitised versions. Lack of control, as cited by many technical managers, is one of the main reasons as to why they are reluctant to share content with third party publishers.
Challenges of Image Retrieval
However, not all libraries partaking in the Europeana Newspapers project appreciate this approach. This is because a fair amount of effort is required to allow images to be technically retrieved in this manner.
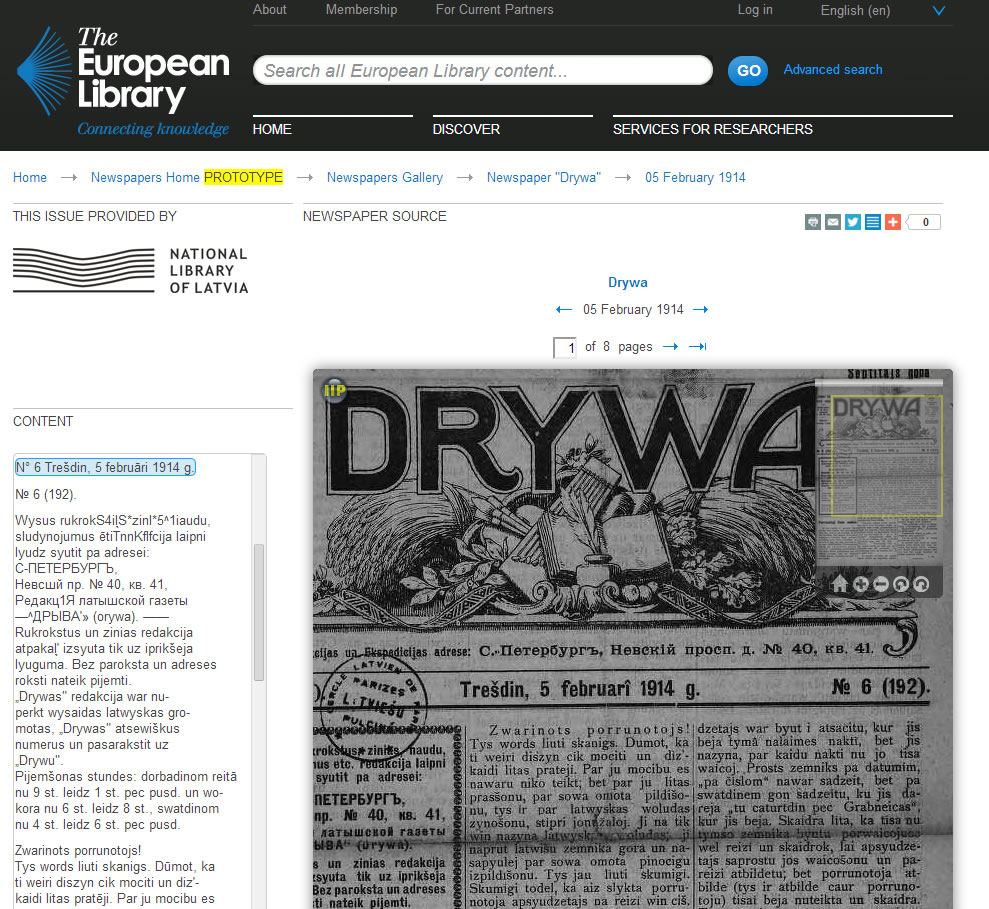
For example, pages from the below 1914 issue of a Latvian newspaper entitled ‘Drywa’ (from the National Library of Latvia) are pre-harvested and stored on The European Library server itself.
Alastair Dunning, Programme Manager at The European Library is excited about the implementation of this image retrieval technique: “As knowledge of this technique increases, I imagine it will become more popular than pre-assembling a collection and having to go through the process of harvesting and then storing the collection, which is time-consuming and costly.”
“This solution implies that third party aggregators will be able to curate, showcase and publish specific collections drawn from a variety of sources. Content will no longer remain trapped in institutional silos and can instead be more easily seen and contextualised in a variety of different settings,” says Alastair.
Where Can I Find the Europeana Newspapers Tool?
The prototype of the Europeana Newspapers tool is now available on The European Library homepage. From there, the user can search for specific historic newspaper titles and browse by various critera such as issue date or country.
Please note that the tool will be user tested in April to assess functionality, report bugs and map the way forward in terms of the tool’s technical requirements. A beta version with improved functionality will be released later this year.
Pingback: The Challenges of Hosting Digitised Newspaper Images & Historic Newspaper Browsing Tool (Prototype) | LJ INFOdocket
Hello…
I am very impressed with your Europeana Newspapers website. Here, we can see to Improved Image Retrieval Technique very easily and step by step. Really its a great
tricks and technique an improved image retrieval. Really,I am very helpful . Thank you sharing for your valuable information.
Hello..!!
I am very impressed with your website. This is an amazing Europeana Newspapers website. Your website article is very informative and helpfully. This information totally focuses on Challenges and Improved Image Retrieval techniques of Hosting Digitised. Really… I am grateful !! Thank You for sharing your valuable information.
Thanks again for this amazing site !!