
One of the main goals of the Europeana Newspapers Project is to create a ‘content browser’ that will allow anyone to easily flip through the pages of the digitised newspapers that are being compiled by the project.
The work to create this browser is being carried out by The European Library, one of the 18 partners in the Europeana Newspapers Project.
When complete, the content browser will also be hosted on a special section of The European Library website. This part of the website will display a mixture of images, full text and metadata that have been aggregated by The European Library as part of the Europeana Newspapers Project. Metadata such as titles of newspapers will also be integrated in the Europeana portal.
What might this content browser look like? First, it’s important to realise that work to create the browser is still at an early stage. There are many different aspects to work on but we do have some wireframes that show our initial ideas.
1. The main page for searching the interface.
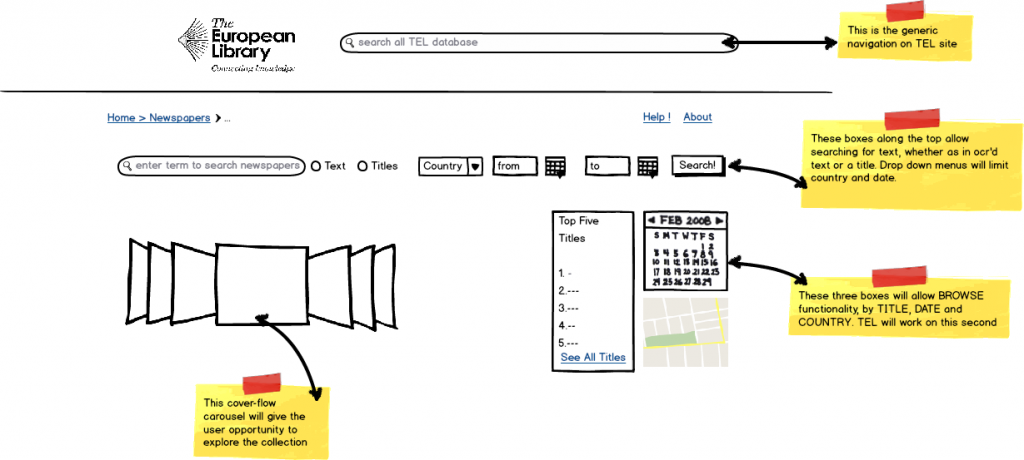
2. The results page after doing a full-text search.

3. A possible page for showing a single page from a newspaper*.
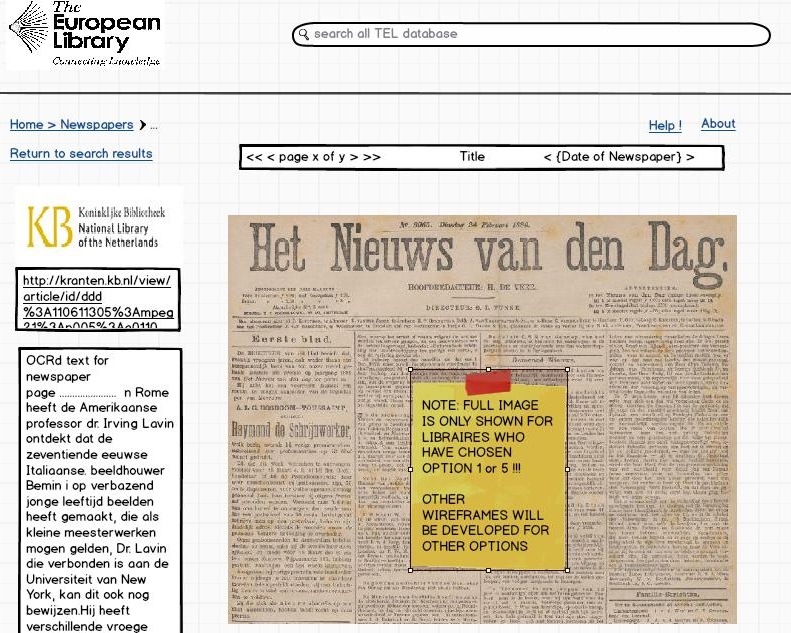
*This will only be relevant for the libraries who have given permission to show entire images.
Work will continue on the interface throughout 2013 and 2014. It is hoped to have a beta version up and running later in 2013. The European Library will continue discussions with all partners to get their feedback.
Do you have thoughts on these sketches? Leave a comment and share your ideas!
For searches about events, newspapers offer opportunities for “more like this”-searches. As events are normally clustered around dates (sometimes with monthly or yearly recurrence), a prominent timeline visualization could be shown together with the search results.
The display of a single page could likewise be augmented by links to the top X pages that also match the originating query, sorted by temporal proximity. A variation would be to use the OCR on the page or ideally the single article to issue a search for similar content, weighted by both similarity and temporal proximity.
Pingback: Leg med avislæser | Avisdigitalisering
The user always needs a content browser for digital newspaper, many people did not know why this will help them, so for those you need to read this post very carefully to know your answer.